サービス概要
Azure データ基盤構築サービスとはMicrosoft Azure の様々な機能を活用し、システムごとに分散したデータから、必要なデータを抽出・加工してひとつの基盤に統合する仕組みを構築します。
ハイブリッド環境でのデータ連携やAI搭載可能なプラットフォーム、全機能がパッケージされた SaaS など、お客様の目的に応じて最適な基盤をご提案します。

解決できる課題
こんな課題に最適です- 必要なデータを必要な時に取得したいが、全体像が不明なためデータの取得に時間がかかっている
- 同じデータが異なる場所で更新されることがあり、データの整合性を維持できなくなっている
- システム単位でデータを管理しているため、データライフサイクルが不透明な状態。全社でデータ管理を統制する仕組みが出来ていない
- Microsoft Azure でデータ連携システムを構築したいが、技術的に精通した人材が社内に不足している
- データ成形や結合を手作業で行っており多くの時間を要する上に、作業手順の共通化が図れていない
- Microsoft Fabric へのデータ移行を実現したいが、多様なデータソースとの連携方式の選定が難しい
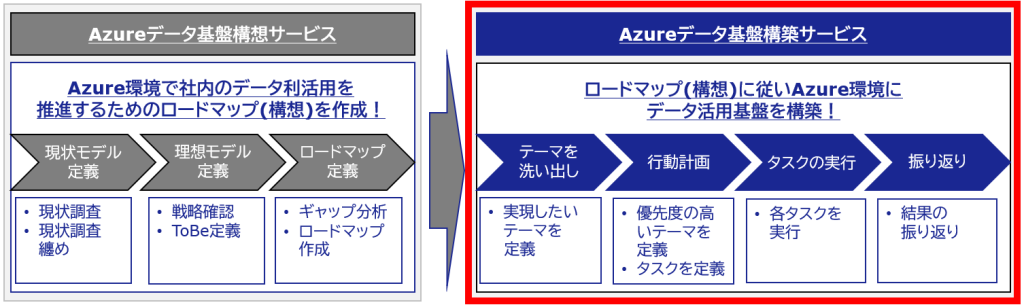
特長・メリット
Azure データ基盤構築サービスを利用するメリットMicrosoft Azure のスペシャリストがお客様に最適な基盤をご提案
弊社は1994年から、Microsoft Technology のエキスパートとしてオンプレミスからクラウドまで、数多くの Microsoft ソリューションを提供してきました。本サービスは、Microsoft Azure の各種機能を熟知し、専門性の高いスキルを持つエンジニアが対応します。
お客様のご要件・環境をヒアリング・調査した上で、お客様のデータ活用目的に合わせて Microsoft Azure の機能を組み合わせ、最適なデータ活用基盤を構築します。
柔軟性とスピードを重視したアジャイル開発方式を採用
データ活用基盤には、大量のデータが蓄積されたり複数システムのデータが集約されたりするため、必然的にシステム規模が大きくなります。
プロジェクトの進め方として、従来はシステム全体の要件定義を定めてから設計・構築へ進むウォーターウォール開発方式を採用するケースが一般的でした。この場合、システム規模が大きいと要件確定に多くの時間を要するため、プロジェクト期間が長期化し、それに伴いコストが肥大化する傾向にあります。
本サービスでは、各種プロセスを短いサイクルで繰り返すアジャイル開発方式を採用しています。サイクル内で発生した問題点や成果を次のサイクルに反映しながら進めることで、プロジェクト期間を短期化するだけでなく、お客様の様々なご要望に柔軟に対応することができます。
ビジネス変化にスピーディーに対応できる運用の仕組みを提供
クラウド環境では、日々変化するビジネス要件に対応するために短期間でシステム変更できることが求められます。
弊社では、Devops パイプラインを活用し、インフラ構築のコード化(IaC)、バージョン管理とデプロイの自動化(CI/CD)ができる仕組みを提供します。これらを利用することで、お客様自身がシステムの解体と再構築を容易に行えるようになります。
運用フェーズにおいても、日々のシステム変更の要求にも迅速に対応することができ、ビジネス変化に強いシステムを構築できます
構成例
目的に合わせた多様なシステム構成弊社は、お客様の目的やご要件や環境に応じて、Microsoft Azure の機能を組み合わせ、最適なシステム構成をご提案しています。
構成例1:DWH 基盤
企業内に分散している様々なデータベース・表形式データを集約し、レポートできる環境構築する場合は、Azure Synapse Analytics を構成することでオンプレミス環境や Azure 環境に存在するデータを統合することができます。
- Self-hosted Integration Runtime を構成することで、オンプレミス環境にあるデータソースを閉域ネットワーク経由で Azure Synapse Analytics SQL Pool に連携できます。
- Azure Synapse Analytics SQL Pool は大量データを蓄積しレポーティングに対応できます。データ量に応じてシステムリソースを拡張することができます。

構成例2:データ分析基盤
大量データの数値モデル計算やデータクレンジング処理のように、システムリソースを大量に必要とする場合は、AI の搭載が可能な Azure Databricks を用いたデータ分析基盤を構築することで高度なコンピューティング処理が実現できます。
- Azure Databricks のライブラリと Apache Spark エンジンを活用することで、複雑なデータ加工処理が実現できます。
- Delta lake 形式でデータを蓄積することで、安価で大量のデータを分析可能な状態に保つことができます。
- Azure Databricks や Azure Synapse Analytics Serverless Pool から機械学習モデルの実行やレポート作成が可能です。

構成例3:ワンストップデータプラットフォーム
データ統合・活用に必要な全機能をワンストップで提供するデータ プラットフォームをお求めの場合は、SaaS 型の Microsoft Fabric を導入することで実現できます。
- Microsoft Fabric は、データ取り込み (Data Factory)、データ レイク (OneLake)、データ加工/分析 (Synapse Data Engineering, Synapse Data Warehouse, Synapse Data Science)、レポート (Power BI) など、データ プラットフォームに必要なすべての機能を備えています。
- OneLake は組織全体で統合された SaaS データ レイクであり、データの移動やコピーを作成することなくデータを共有できるサービスです。
- Synapse Data Engineering は Apache Spark を使用して大量データを効率よく処理することが出来ます。

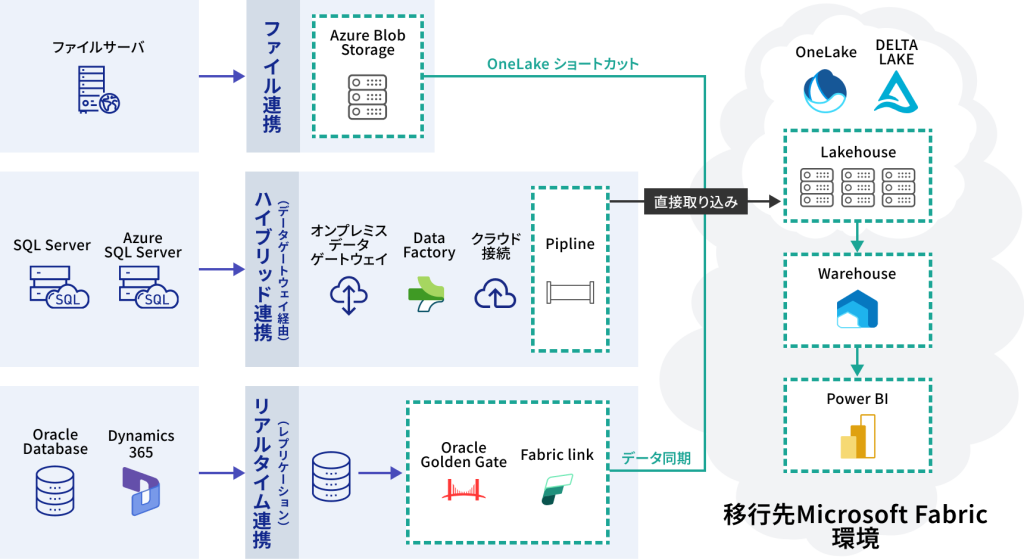
機能・仕様
サービス詳細・仕様Microsoft Azure エンジニアによる役務提供型サービスとなります。弊社(リモート含む)から Azure 環境に接続し、構築作業を実施します。
履行割合型の準委任契約で、1か月あたりの作業工数×エンジニア単価の提供となります。そのため、進捗状況等により、稼働時間増減に応じて毎月のサービス費用が変動します。
お客様にてご準備いただくもの
- Microsoft Azure サブスクリプションのご契約
- Microsoft Azure サポート リクエストが可能な Azure サポートプランのご契約
- Microsoft Azure サブスクリプション アカウントの弊社エンジニアへの無償提供
- 貴社オンプレミス環境と Microsoft Azure 環境間をプライベート接続する必要がある場合は、予めExpress Route や VPN 等
- お客様環境を利用する際に専用の機器が必要となる場合は、必要な機器 (ハードウェア、ソフトウェア、ネットワークを含む)
導入までの流れ
データ活用基盤導入までの流れ各種プロセスを2~4週間程度の短いサイクルで繰り返していくことで、スプリント(※) 内で発生した問題点や成果を次のサイクルで反映しながら進めることで、プロジェクト期間を短期化するだけでなく、お客様の様々なご要望に柔軟に対応できます。
※スプリントとは
アジャイル開発の手法の一つであるスクラムの基準となる考え方です。スクラムは小さな単位でシステムに必要な機能の計画と実装を繰り返す開発手法で、この反復の単位をスプリントと言います。
【サイクル内の各タスク】

費用
Azure データ基盤構築サービスの費用システムの規模や構成、お客様のご要件によって変動するため、個別見積となります。
このページの製品に関するご相談はこちら
本ページの製品・サービスに関するご相談からお見積もり依頼まで承っております。
まずはこちらからお気軽にご相談ください
