近年、デジタルトランスフォーメーション(DX)の波が各業界に押し寄せ、自社でシステム開発を内製化する動きが注目されています。しかし、システム開発を内製化する際には、専門的な知識が必要となるため、多くの企業が直面する課題も少なくありません。本コラムでは、Microsoft社のSaaSソリューション「Microsoft Fabric」を取り上げ、専門知識がなくてもデータ活用基盤を自分たちの手で構築・運用する方法を紹介します。
近年のシステム開発ではDXの考えが浸透し変化に強くスピーディーな対応が求められています。このため、システムを利用する企業がシステム開発を内製化(自社開発)する手法が注目されています。
これまでのアウト ソーシングが中心のシステム開発では、システムがブラック ボックスになるリスクがありました。これにより、自社で使用するシステムにも関わらず、社内にノウハウが蓄積されず、スピーディーに対応できないことが課題になっていました。
その対策として、システム開発をするために必要なIT技術を有していなくも開発を可能とする様々なローコード、ノーコード プラットフォームが登場しています。
現在のローコード、ノーコード プラットフォームは主にアプリケーション開発に焦点があたっていますが、当然ながら自社で利用するシステムはアプリケーションだけではありません。自社に蓄積されたデータを一元管理し、必要な時に必要な情報をスピーディーに取得してビジネス創出に活用するための、データ活用基盤も重要です。
システム開発をアウト ソーシングすること自体が問題ではありませんが、機能の追加や変更の度に外部委託先に要件の説明や契約手続きが発生し、現実的な問題として迅速な対応の妨げになることがあります。
それではなぜシステムを利用する自社では構築や機能変更が難しいのでしょうか。近年、クラウド サービスの利用が一般的になっており、PaaSソリューションを活用すれば専門知識は不要なのでは?という疑問を持たれるかもしれません。
例として、Azureサービスを利用して構築する場合をイメージし、なぜ自社で開発するのが難しいのかを探ってみます。
Azureサービスに関する様々な専門知識が必要
データ活用基盤を構築する場合、データ格納領域や分析領域、レポート領域など、通常様々なサービスを構築する必要があります。また、利用するサービスをフル マネージドなサービスで選定したとしても、業務利用するためには構築時に各設定項目を適切に構成する必要があります。
サービス レベルはどれを選択するのが適切なのか、可用性の向上はどうすればよいのか、各認証情報は何処で管理するのか等、利用するサービス全てにおいて専門的な知識が必要になります。データ利活用基盤をイメージした場合、以下のような各サービスの専門知識が必要です。
- データ格納領域:Azure SQL Database、Azure Storage Account など
- 分析領域:Azure Databricksなど
- レポート領域:Power BIなど
データ連係の専門知識が必要
データ活用基盤は各システムのデータを一元的に管理する必要があるため、データ格納領域などのインフラを構築するだけでは実現できません。各システムからデータを連係するための専門知識が必要になります。
- Azureサービスの中でETL(Extract/Transform/Load)サービスの役割を担うAzure Data Factory(パイプライン)の専門家
- プログラミングで連携を実現する場合は、Azure Functionsなどのサーバーレス アプリケーション開発の専門家
データ抽出の専門知識が必要
データ格納領域としてAzure SQL Databaseを利用することは一般的な手法です。Azure SQL Databaseを利用する場合、テーブル作成やデータ抽出にクエリを利用する必要があるため、クエリの専門知識が必要となります。
上記の通り、データ活用基盤を利用できるようにするためには、様々な専門知識が必要になります。また、上述の内容では詳細な技術要素を割愛していますが、これらの他にもサービス間のネットワーク設定や権限制御(ロール)の設定、PaaSソリューションを組み合わせる構成などにおいて、AzureやIT全般の知識が求められ、簡単には自社で構築や機能変更を進めることが難しいのです。
専門的な知識を必要とせず自社でデータ活用基盤を構築する手段として、Microsoft社が提供するSaaSソリューション「Microsoft Fabric」があります。
「Microsoft Fabric」はデータ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンスまでのすべてをカバーする企業向けのオールインワン分析ソリューションです。データ レイク、データ エンジニアリング、データ統合などのサービスがすべて1箇所で提供されます。 では、どのようにすれば自社で構築することができるのでしょうか。上述した内容を踏まえ、ポイントを絞って説明します。
構築作業が不要
データ活用基盤をAzureの機能で構築する場合、構築のための設計や構築作業の工程が必要になります。
一方、「Microsoft Fabric」はSaaSソリューションのため、それらの作業が必要ではなく、専門的な知識が無くてもアカウントを作成すればすぐに利用を開始できます。
また、「Microsoft Fabric」は、オールインワン分析ソリューションのため、データ格納機能だけにとどまらず、分析機能やレポート機能も利用できます。
アウトソーシングによるPaaSソリューションの組み合わせで構築を実施した場合、各設定がブラック ボックスになる恐れがありましたが、「Microsoft Fabric OneLake」(「Microsoft Fabric」)はSaaSソリューションのため、その懸念が無く利用できます!
データ連携の専門知識が無くても連係処理の実現が可能
「Microsoft Fabric」は「Microsoft Fabric OneLake」と呼ばれる組織全体で 1 つに統合された論理データ レイクをデータの格納領域としています。「Microsoft Fabric OneLake」は、Azure Data Lake (ADLS) Gen2 上に構築されており、テナントと呼ばれる大きな領域にデータが格納されます。
テナント内には、組織ごとの境界を設けるためのワークスペースを作成することができ、このワークスペースを組織に関連付けることも可能です。さらに、ワークスペース内にレイクハウスを作成し、システムごとにデータ(ファイル)が格納される仕組みになっています。

「Microsoft Fabric」内は、そもそもデータ連携が不要です。他システムや他組織、データ一元管理している格納領域にデータを共有したい場合、これまではデータをコピーするのが一般的でした。「Microsoft Fabric OneLake」では、「ショートカット」機能が備わっているため、データをコピーしなくてもデータの共有が可能です。
また、「ショートカット」機能の作成にも専門的な知識は不要で、手順さえ覚えてしまえば、GUIベースで簡単に操作することができます。
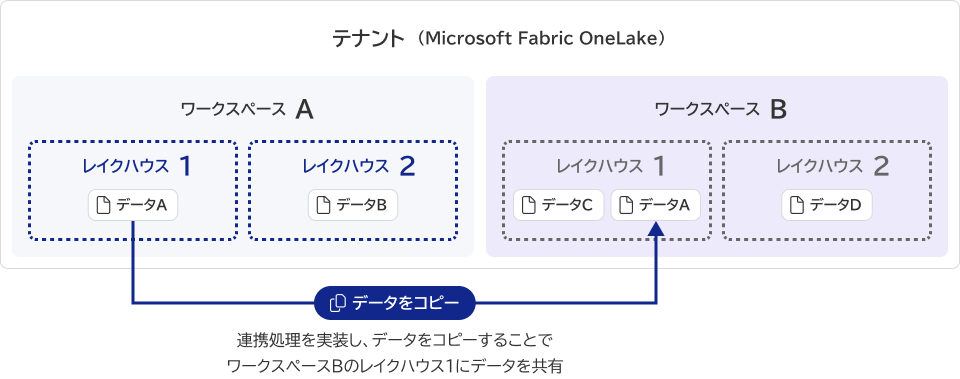
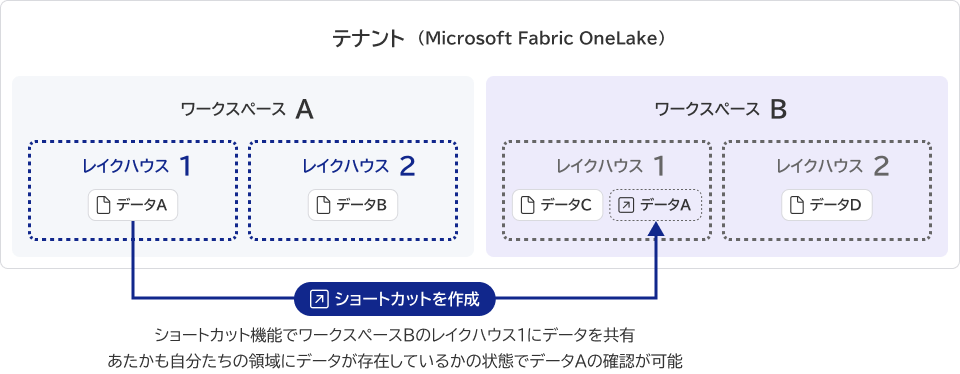
データコピーの実装が不要になることで、データコピーでは問題となる恐れがあった各組織(システム)でデータの整合性が取れなくなることや、データの鮮度の違いなども解消されます!
十分な知識が無くてもデータ抽出が可能
他システム等から連携されるCSVファイルをAzure SQL Databaseのテーブルに格納しデータを抽出する場合、一般的には以下のステップが必要になります。
- テーブルの作成
- CSVファイルをテーブルにインポート
- データの抽出
この全ステップでクエリの専門知識が必要となります。しかし、「Microsoft Fabric」の場合、この一連のステップが必要ありません。
クエリの知識がなくても、簡単なGUI操作で、①~③の作業が可能です。単純な抽出だけでなく、条件指定(フィルター)や並べ替え等の操作も可能です。
加えて、「Microsoft Fabric」はMicrosoft社が提供する生成AI機能「Copilot」と統合されているため、専門知識がなくでもパイプライン(Data Factory)などを実装することが可能です。
これまでの説明では、主にGUI操作で実現できる機能のメリットを強調しましたが、利用を進める中で実装が必要な場面も出てくるでしょう。一般的に実装には専門的な知識が求められますが、「Copilot」を利用することで専門知識がなくても機能を実現できる可能性が高まります。
例えば、「ショートカット機能」を使わずにパイプラインでデータを連携(共有)したい場合は、「Copilot for Data Factory」を利用することができます。「Copilot for Data Factory」は、ワークフローを合理化するための AI 拡張ツールセットです。 基本的に「Copilot for Data Factory」は、データフロー設計の専門家のように動作します。これまでのパイプライン作成には、少なからず専門知識が必要でしたが、パイプラインの知識が浅い場合でも「Copilot for Data Factory」を利用することで、パイプライン作成を進めることができます。
「Microsoft Fabric」は構築を必要とせず、専門的な知識がなくても利用できる様々な機能を提供しています。それらの機能を利用することで、アウト ソーシングで専門家に頼らずに自社でデータ活用基盤の構築を進めることが可能です。これにより、自社内にナレッジも蓄積することができます。
また、今回は「Microsoft Fabric」の一部の機能を紹介しましたが、他にも分析やレポート等、様々な機能が備わっています。迅速な対応を実現するために、自社でデータ活用基盤の構築や利用を進めたい場合「Microsoft Fabric」の利用を検討してはいかがでしょうか。
SCSK Minoriソリューションズでは、データ利活用基盤の利用や構築をご支援するサービスを提供しています。データ利活用基盤を実現するうえでお困りのことがありましたら、ぜひお気軽にご相談ください。


